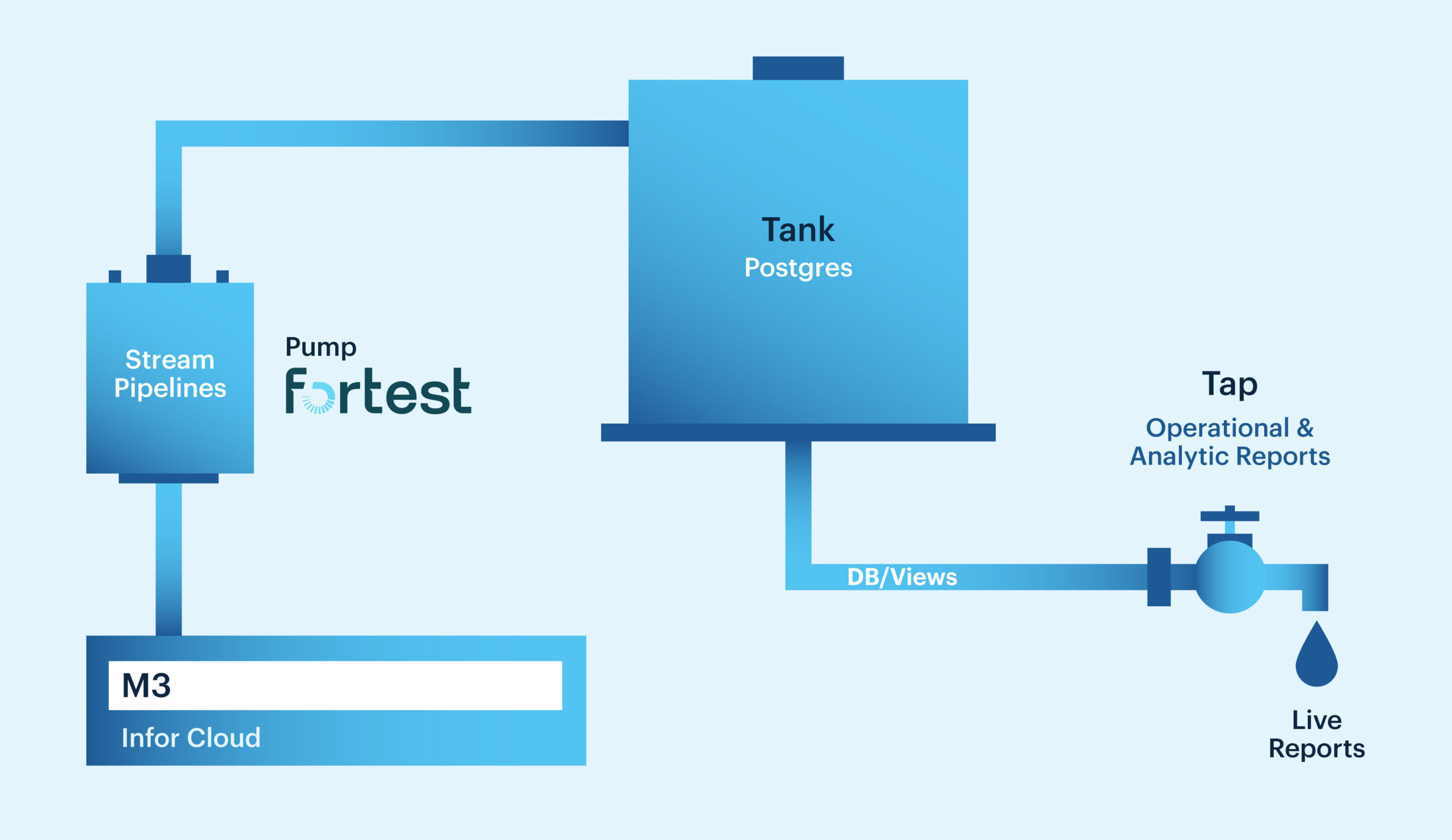
Once out, where do you store the data? Your options include Postgres on Amazon Aurora or Azure, or Snowflake. For our pilot, we chose Azure SQL, which cost us around $3K/year for a basic setup.
💡 We used an “upsert” method instead of traditional inserts — it’s more efficient and ensures you’re always looking at the latest data snapshot.